Cyclistic: A Chicago Bikeshare Case Study
This case study is an analysis of real historical data from Chicago-based bike-share company Divvy (in this scenario a faux company called Cyclistic) to determine behavioral trends in different customer types. The tools I used were Excel spreadsheets, BigQuery SQL, and Tableau. I’ve linked the important bits:
The full report can be viewed below.
Scenario
Cyclistic is a Chicago bike-share company with two types of customers: casual riders who purchase single-ride or full-day passes, and member riders who purchase annual memberships. Financial analysts at Cyclistic have concluded that annual members are much more profitable than casual riders. The director of marketing believes the company’s future growth and success depends on maximizing the number of annual memberships.
Rather than creating a marketing campaign that targets all-new customers, the director of marketing believes there is good opportunity to convert casual riders into members. The primary stakeholders for this project are the director of marketing and the executive team. The secondary stakeholders are the marketing analytics team.
Defining the goal
The director of marketing set a clear goal: Design marketing strategies aimed at converting casual riders into annual members. To do this, the marketing analyst team must better understand how the member types differ. The following three questions guide the future marketing program:
How do annual members and casual riders use Cyclistic bikes differently?
Why would casual riders buy Cyclistic annual memberships?
How can Cyclistic use digital media to influence casual riders to become members?
The project assigns the first question as the focus of this case study. Finding the answer relies on historical data to find patterns in customer behavior, which will provide insights that will help the marketing analytics team design a well-researched targeted marketing strategy for user conversion. This will ultimately benefit the Cyclistic executive team, for which the insights will help Cyclistic maximize the number of annual members and will fuel future growth for the company. The business task is defined as such:
Analyze historical trip data to determine patterns in how casual riders and member riders differ.
Data Sources
We will be looking at historical bike trip data from the last 12 months available at the time of this project. The data is available here and made available under this license agreement. The data is stored in 12 CSV files:
202208-divvy-tripdata.csv 202209-divvy-tripdata.csv 202210-divvy-tripdata.csv 202211-divvy-tripdata.csv 202212-divvy-tripdata.csv 202301-divvy-tripdata.csv 202302-divvy-tripdata.csv 202303-divvy-tripdata.csv 202304-divvy-tripdata.csv 202305-divvy-tripdata.csv 202306-divvy-tripdata.csv 202307-divvy-tripdata.csv
Each trip is anonymized and unfortunately cannot be linked to individuals’ trip history to further assess rider behavior. Each record represents one bike trip and can be identified by unique field ride_id. The fields are organized as follows:
* ride_id #Ride id - unique * rideable_type #Bike type - Classic, Docked, Electric * started_at #Trip start day and time * ended_at #Trip end day and time * start_station_name #Trip start station * start_station_id #Trip start station id * end_station_name #Trip end station * end_station_id #Trip end station id * start_lat #Trip start latitude * start_lng #Trip start longitude * end_lat #Trip end latitude * end_lat #Trip end longitude * member_casual #Rider type - Member or Casual
I also used data provided by the City of Chicago on Bicycle Stations for more accurate geographic location data. Here are their usage terms and here is where you can access the data.
There are no bias or credibility concerns with the data at hand, and the data used is in line with these conditions:
Reliable and original: This is public data that contains accurate, complete, and unbiased info on this company’s historical bike trips.
Comprehensive and current: These sources contain all the data needed to take on the business task of understanding the different ways member and casual riders use Cyclistic bikes. The data utilized spans the last 12 months, ensuring its relevance to the current task. This is crucial as the effectiveness of data diminishes over time.
Cited: These sources are publicly available data provided by the bike company and the City of Chicago. Government data and vetted public data are typically reliable sources.
Because of this, I know my data ROCCCs!
Importing and cleaning the data
I downloaded the data into a local folder on my computer as zipped files and unzipped them into another folder I made to house the CSV files. I initially did all my cleaning and created new columns in Excel, but I wanted to showcase my work in SQL, so my next relevant step was to import all my data files into BigQuery SQL by uploading them to Google Cloud Storage (GCS). I then created 12 new tables with the same names as the files in BigQuery, and populated the schema with auto-detection.
Setting up shop
For the first query I created an empty table to house the aggregate data:
CREATE TABLE bikeshare.year_aggreg ( ride_id string, rideable_type string(50), started_at timestamp, ended_at timestamp, start_station_name string(100), start_station_id string, end_station_name string(100), end_station_id string, start_lat float64, start_lng float64, end_lat float64, end_lng float64, member_casual string(50) )
I then inserted the datasets I loaded into the empty table I created.
INSERT INTO bikeshare.year_aggreg SELECT * FROM `resolute-might-399613.bikeshare.202208` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202209` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202210` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202211` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202212` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202301` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202302` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202303` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202304` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202305` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202306` UNION ALL SELECT * FROM `resolute-might-399613.bikeshare.202307`
In this query, I added a ride length column:
ALTER TABLE `resolute-might-399613.bikeshare.year_aggreg` ADD COLUMN ride_length float64;
I then assigned values to column ride_length
by taking the timestamp of ended_at and subtracting it from
started_at. By default, the time is in seconds.
UPDATE `resolute-might-399613.bikeshare.year_aggreg` SET ride_length = TIMESTAMP_DIFF(ended_at, started_at, SECOND) WHERE ended_at = ended_at
I divided the column values by 60 to put the ride length in minutes.
UPDATE `resolute-might-399613.bikeshare.year_aggreg` SET ride_length = ride_length/60.0 WHERE ended_at = ended_at
I created another table to house new columns that were dependent on columns that already existed: a month column, a year column, and a year and month combined column.
CREATE TABLE `resolute-might-399613.bikeshare.year_aggreg_for_ana` ( ride_id string, rideable_type string(50), started_at timestamp, ended_at timestamp, ride_length float64, day_of_week int64, month int64, year int64, yearmonth string, start_station_name string(100), start_station_id string, end_station_name string(100), end_station_id string, start_lat float64, start_lng float64, end_lat float64, end_lng float64, member_casual string(50) )
INSERT INTO `resolute-might-399613.bikeshare.year_aggreg_for_ana` SELECT ride_id, rideable_type, started_at, ended_at, ride_length, EXTRACT(DAYOFWEEK FROM started_at) AS day_of_week, EXTRACT(MONTH FROM started_at) AS month, EXTRACT(YEAR from started_at) AS year, CONCAT(CAST(EXTRACT(YEAR from TIMESTAMP(started_at)) as string), LPAD(CAST(EXTRACT(MONTH from TIMESTAMP(started_at)) as string),2,'0') ) AS yearmonth, start_station_name, start_station_id, end_station_name, end_station_id, start_lat, start_lng, end_lat, end_lng, member_casual FROM `resolute-might-399613.bikeshare.year_aggreg`
Investigation and clean-up
In the next query, I checked for duplicate values of ride_id.
SELECT * FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE ride_id IN (SELECT ride_id FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` GROUP BY ride_id HAVING COUNT(ride_id) > 1 ) #results yielded nothing
No duplicate ride ID values, so I moved on to looking at the maximum and minimum ride length values.
SELECT count(ride_id), min(ride_length) as min, max(ride_length) as max FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana`
This query yielded the following table:

…which is concerning to say the least. I looked at the highest ride length values to inspect for a potential pattern:
SELECT * FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` ORDER BY ride_length DESC LIMIT 100
From this query, I could see that the maximum ride length values were disproportionately docked bikes and casual riders. Below, you can see I queried the important bits and the first 15 rows of the table.
SELECT rideable_type, start_station_name, end_station_name, member_casual, ride_length FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` ORDER BY ride_length DESC LIMIT 100

You can also see the rides are grouped together based on ride length, whereas rides of length within a range are all from the same starting station. The rides are additionally only by casual riders and have no end station implying they don’t move from the start station, which is likely the meaning of the rideable type being a docked bike.
I researched a little further and discovered that a docked bike is one that the company took out of circulation to assess for quality control, and thus should be omitted from the dataframe.
I also looked at the flip side— that is, the shortest bike ride lengths (negative values), and the shortest docked bike ride lengths. The following query is for the shortest docked bike ride lengths:
SELECT rideable_type, start_station_name, end_station_name, member_casual, ride_length FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE rideable_type = "docked_bike" ORDER BY ride_length LIMIT 100
This yields the following table:
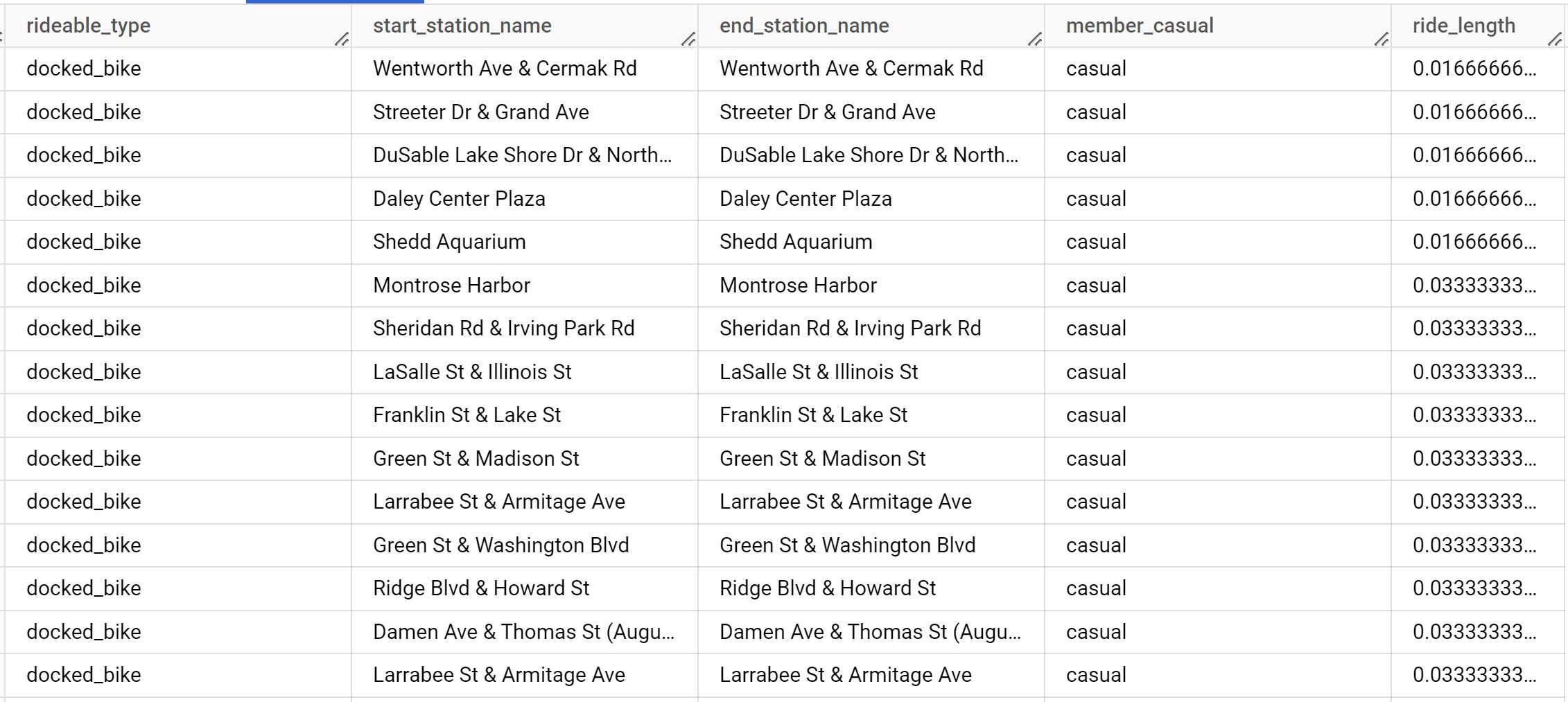
Interestingly, these all have an end station name listed, though the same as the start station name. The ride lengths also all seem to be valid. The next query is for the shortest ride lengths overall:
SELECT rideable_type, start_station_name, end_station_name, member_casual, ride_length FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` ORDER BY ride_length LIMIT 100

There is no rhyme or reason to these values— variation in bike type, rider type, and missing values between start station and end station— implying a lack of purpose in these rows of data. I can only assume the negative rides are somehow caused by errors in recording data as there should be no way someone has a negative value for ride length.
Removing rows, I chose to scrub all the docked bike “rides”, negative values, and values over 24 hours from the data.
To begin, I filtered for unreasonably long rides where ride_length was over 24 hours, or 1440 minutes. I chose to allow rides up to 24 hours since casual riders can purchase whole day passes.
SELECT * FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE ride_length > 1440
I then removed those rows from the data.
DELETE FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE ride_length > 1440 # 5,292 rows removed
I then removed instances where ride_length was less than or equal to zero.
SELECT * FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE ride_length < 0 OR ride_length = 0
DELETE FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE ride_length < 0 OR ride_length = 0 # 715 rows removed
I lastly removed all rows with rideable_type value docked_bike.
SELECT * FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE rideable_type = "docked_bike"
DELETE FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE rideable_type = "docked_bike" # 126,966 rows removed
Analysis
Summary statistics in SQL
I jumped into looking at overarching statistics after cleaning up. As a forewarning I do want to mention I’m not the most consistent in variable naming syntax here because it seems depending on who it is, the preference changes! I apologize if it hinders readability.
I first looked at ride count of all riders, members and casual riders, and what percentage each makes up of total rides.
SELECT
TotalRides,
TotalMemberRides,
TotalCasualRides,
ROUND(TotalMemberRides/TotalRides,2)*100 AS MemberPercentage,
ROUND(TotalCasualRides/TotalRides,2)*100 AS CasualPercentage
FROM
(
SELECT
COUNT(ride_id) AS TotalRides,
COUNTIF(member_casual = 'member') AS TotalMemberRides,
COUNTIF(member_casual = 'casual') AS TotalCasualRides,
FROM
`resolute-might-399613.bikeshare.year_aggreg_for_ana`
)
Members make up the majority of rides by a long shot, clocking in at 64.0%, in contrast to casual rides only making up 36.0% of rides.
Ride length
I next looked at at average ride length:
SELECT member_casual, count(ride_id) as TotalRides, avg(ride_length) as AverageRideLength FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` GROUP BY member_casual

Members seem to ride for a shorter amount of time on average than casual users. This could be for a variety of reasons. Perhaps because casual users have the opportunity to get day passes they opt to ride for longer to take advantage of their single day they have on the bike, or maybe because they aren’t members they ride more infrequently and are more likely to make the most out of their bike ride and ride for leisure, while members may be more likely to use their ride as simply a quick mode of transportation.
Rides by days of the week
I next wrote a query to see the difference in ride count and length over the days of the week, 1 being Sunday and 7 being Saturday.
SELECT day_of_week, member_casual, count(ride_id) as total_rides, avg(ride_length) as average_ride_length FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` GROUP BY day_of_week, member_casual ORDER BY member_casual, day_of_week

We can see here casual rides peak in numbers and length on the weekends and the difference between weekend vs. weekday riding is very large. Members peak during the week in numbers and are more consistent in overall ride count, but seem to also ride for a little longer on the weekends. Members also seem to consistently ride more similar amounts of time on average while casuals have more variance. It seems everyone likes to take it slower on the weekends. This could be because most people work M-F jobs and weekends allow everyone more leisure time for joyrides and/or riding to further away, more unfamiliar places for weekend activity, but members are likely to still be using their bikeshare membership for transportation from A to B in large proportion while some member riders are also taking weekend joyrides.
Rides by Month
I next looked at the ride count and length averages over the months:
SELECT yearmonth, member_casual, count(ride_id) as total_rides, avg(ride_length) as average_ride_length FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` GROUP BY yearmonth, member_casual ORDER BY member_casual, yearmonth
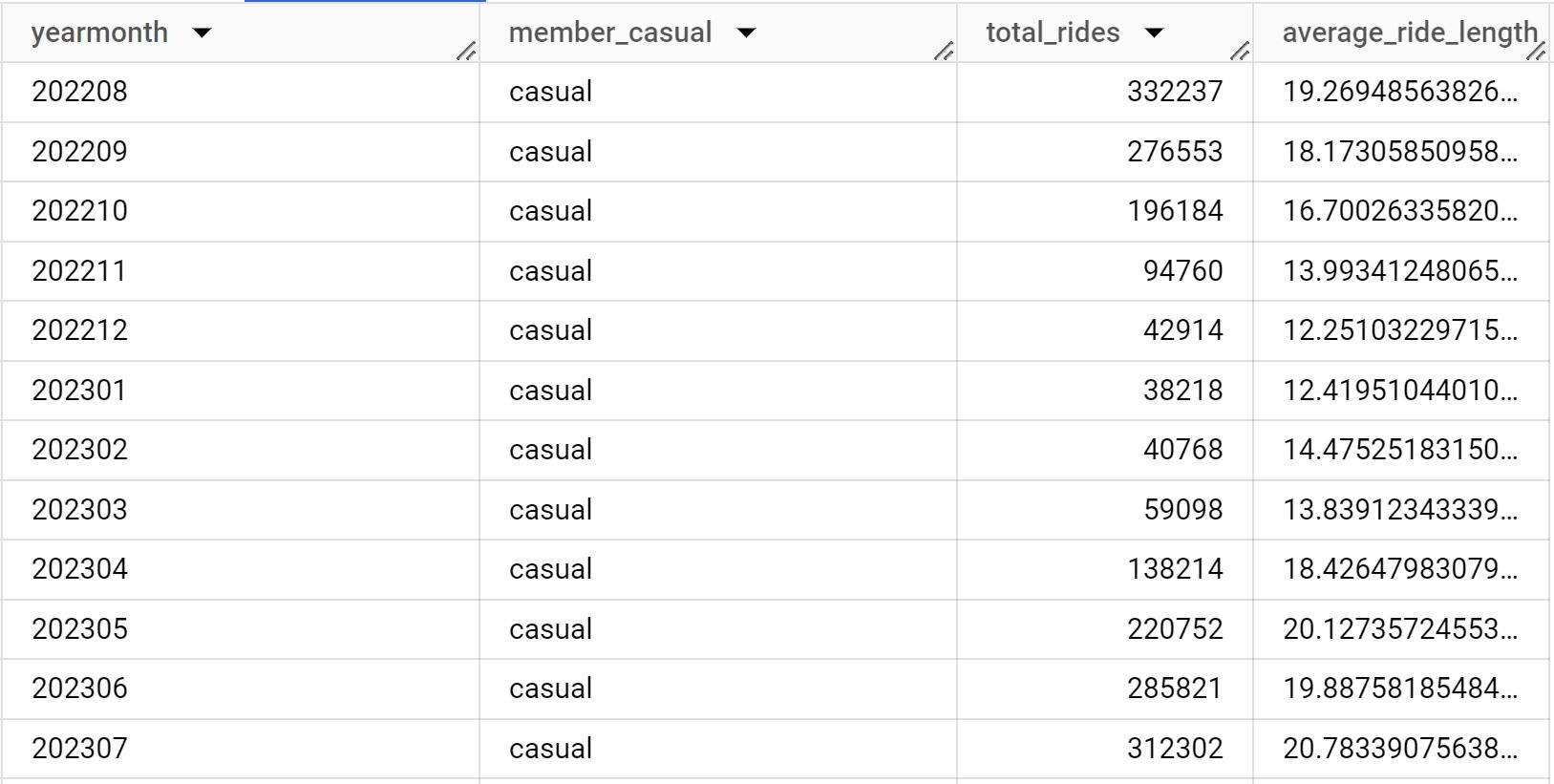

Once again there seems to be a bell curve in ride count and average ride lengths since I’ve caught the most recent data at a time where the ends are the warmest months most conducive to comfortable riding weather.
We can see that member rides are more consistent with ride counts and lengths throughout the colder months while casual rides drop significantly in both columns. Regardless, it seems everyone hates biking in December, or any colder month for that matter, especially in the windy city Chicago where the weather can easily drop below freezing during the winter.
My last interest was looking at the most frequented stations.
Station popularity
I began with a query to return the top 10 most used start stations:
SELECT start_station_name as StartStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE start_station_name != 'null' GROUP BY start_station_name ORDER BY RideCount DESC LIMIT 10
I then looked at the end stations.
SELECT end_station_name as EndStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE end_station_name != 'null' GROUP BY end_station_name ORDER BY RideCount DESC LIMIT 10
If you compare the two, 10 out of 10 stations are shared between the most popular start and end stations— that is, people are coming and going about just as frequently.


Now let’s look at the difference between member and casual riders.
SELECT start_station_name as StartStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE start_station_name != 'null' AND member_casual = "member" GROUP BY start_station_name ORDER BY RideCount DESC LIMIT 10
SELECT end_station_name as EndStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE end_station_name != 'null' AND member_casual = "member" GROUP BY end_station_name ORDER BY RideCount DESC LIMIT 10
SELECT start_station_name as StartStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE start_station_name != 'null' AND member_casual = "casual" GROUP BY start_station_name ORDER BY RideCount DESC LIMIT 10
SELECT end_station_name as EndStation, COUNT(*) as RideCount FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana` WHERE end_station_name != 'null' AND member_casual = "casual" GROUP BY end_station_name ORDER BY RideCount DESC LIMIT 10
These queries yield the following tables:




Member start station and end station popularity perfectly overlap 10/10 while casual overlaps 9/10. People are coming and going all the same— this makes sense if you’re using bikeshare as your main or only mode of transportation; if you get yourself somewhere you have to get yourself out.
One thing to note is that most popular member start station numbers are a lot lower— perhaps the location concentration is lower due to members using bikes depending on where they live or work, which varies greatly, rather than in popular areas for activity or tourism. Looking at some of the popular casual station names— Millennium Park, Shedd Aquarium, Theater on the Lake, DuSable Lake Shore, Dusable Harbor— these are areas of leisure activity where one can go to the park, aquarium, theater, or waterfront, primarily on the lake. Member stations are, predictably and funnily enough, concentrated greatly around the Chicago Loop, which is the city’s central business district. This is all visible in the Tableau visualization!
Due to start and end station overlap, I can comfortably use only start station to represent station popularity for each ride type and take a closer look at how casual, member, and all rider type station popularity compare, which I do next.



Between overall and casual, there are 5/10 stations that overlap in the top 10 most used stations, while between overall and member there are 6/10 stations that overlap. This implies that despite casual rides only making up 38% of rides, they contribute a proportionally significant amount to the stations with a high concentration of use, while member rides may be more spread out. Between casual and member top 10 stations, there is only one station overlap: Wells St & Concord Ln. Very interesting that casual and member riders hardly prioritize the same riding locations!
Some more considerations are seasonality and temporality of rides, which I explore further after exporting to Tableau.
Exporting to Tableau
I wanted to export the whole table to GCS and download the file to a local folder from there to upload to Tableau Public; however the file is over 1 gigabyte and too big for BigQuery to export, so I had to write a query to split the table:
CREATE TABLE `resolute-might-399613.bikeshare.year_aggreg_processed` PARTITION BY RANGE_BUCKET(export_id, GENERATE_ARRAY(0, 1, 1)) CLUSTER BY export_id AS ( SELECT *, CAST(FLOOR(1*RAND()) AS INT64) AS export_id FROM `resolute-might-399613.bikeshare.year_aggreg_for_ana`)
I chose 1 partition where my n = 1 and exported it in the following query:
EXPORT DATA OPTIONS( uri='gs://bikeshare-case-study/*.csv', format='CSV', overwrite=true, header=true, field_delimiter=';') AS SELECT * EXCEPT(export_id) FROM `resolute-might-399613.bikeshare.year_aggreg_processed` WHERE export_id = 0;
This query exported the table to GCS into 21 files of 57.8Mb named 000000000000.csv through 000000000020.csv. I download all of the files into a local folder on my desktop and then upload them onto Tableau Public, where I had to union all the tables back into one.
I do not recommend this method. In a union of 21 files, the engine cannot fully optimize requests and extractions and easily times out. Tableau Desktop can directly connect to Google BigQuery and Tableau Prep is great for piecing together files into one whole sheet. However, neither of these are free resources and Tableau Public can only connect to Google Drive.
Analysis and visualization in Tableau
Below is the data I exported into Tableau Public in a variety of visualizations, along with accompanying analysis and insights. You can access the summarization and visualization here on Tableau!
Rides by day of the week

Casual riders have a strongly defined U-shape over the week, peaking in ride length times on the weekends. Member riders also have a weakly defined U-shape, but maintain a rather consistent ride time average, potentially indicating that members are more likely to ride for similar reasons across the week that do not demand long ride times, while casual riders may have more variety in reasons to ride (say, regularly commute to work and not biking for other reasons as much vs occasionally commuting to work and occasionally riding for fun on the weekends in greater proportion).

Ride count tells a more fun story where total rides over the days of the week make almost inverse U- and N-shapes for casual riders and member riders respectively. Casual riders seem to ramp up over the week and peak on the weekends, while member riders peak in the middle of the week. Ridership seems to tell a story of more use for work or play depending on the type of customer.

Here’s another look at the ride count using an area chart showing the proportionality of rides by rider type.
Rides by month

Ride length dips for both rider types in the colder months, much more significantly for casual riders.

Ride count suffers greatly and dips prominently for both customer types, with incredibly poor retention of casual riders, something to definitely keep in mind while discerning the differences and how to market.

Another look at the ride counts with the area chart. The most popular month for riding is July, with August and June also being popular.
Looking at medians
Now let’s look at median values for potentially more accuracy and to compare with averages!

This is a significant reduction from the average ride lengths of 18.5 minutes for casual riders and 12.0 minutes for member riders, but maintains the trend of casual riders averaging higher.


As you can see, there is a significant reduction in the difference between the median ride lengths of casual riders and members across the days of the week and months, implying the majority of casual riders are probably using the bike share service to get from point A to point B, while a smaller percentage are using the bike share service for longer, more leisurely use. Still, important to note that people can do full-day passes and how it may affect mean value.
Month and week combined visualizations
The following charts combine the months and weeks for a more comprehensive look at the distribution of rides.

You can see above that casual riders only outride members on Saturdays in June, July, August, and September, and on Sundays in August. Summer-loving runs rampant in the casual crowd!
The following is my favorite visualization I made for the data, utilizing color and dot size to signify comparative ride volume very clearly. I left this off of the Tableau summary visualization as it diluted the distinction of differences between casual and member riders, but is fun and informative nontheless.

Below you can see max rides for the day of the week through the months. To get the field in Tableau, I input the following calculation:
IF COUNT([ride_id]) = WINDOW_MAX(COUNT([ride_id])) THEN "Max" ELSE "N/A" END

Members consistently peak on the weekdays, except in June 2023 which has a peak on Friday. This doesn’t necessarily count as a weekend, but is an interesting change to potentially note as the weather in June warms and is the segue into the weekend.

The casual riders are especially interesting to see through the months and days of the week; through the warmer months casual riders are much more likely to peak on the weekends, namely Saturday, but during the cold times it’s likely no one is riding for fun on the weekends because it gets much too cold in Chicago so the peak rides are during the week when people decide to commute to/from work. The casual riders choosing to purchase single rides on the weekdays during the cold months as a form of transportation are probably the best candidates for annual memberships, something to consider while designing a marketing strategy.
Rides by the hour of the day

Member ride counts experience a large peak at 8 am and the largest peak at 17, or 5 pm. This is likely in line with members’ work hours! Casual ride counts experience a steady rise over the day from 4 am to a peak at 5 pm, likely because during the weekend casual riders are riding throughout the day, but during the week they are choosing to commute home from work in greater volume than other uses. There is probably less incentive for casual riders to commute to work from home due to inconvenience or simply not wanting to in the early hours of the day.
Electric or acoustic?

Members are split pretty evenly on preference but casuals seem to prefer electric, perhaps because casual riders are more likely to be using bike share for leisure and want to try something new or more fun.
Quarter/season analysis

I split the months into seasonal quarters to do a seasonality/quarterly analysis. As discovered previously, the best season to market is likely summer or leading into summer, when there are the most casual riders (and riders overall) and they are most optimistic about riding
Following are the average and median ride length by quarter, and max ride by quarter.



No surprises here! A great simplification from months leaves little to be analyzed past what has already been noted.
Mapping rides



Click through the carousel to see the difference between member and casual riders as noted in the SQL analysis. Members are significantly more spread out and in a completely different area than casual riders!
Conclusions
Once again, you can access the visualization here on Tableau, and the stakeholder presentation here for an in-depth conclusion!
Primary differences between member and casual riders are:
Seasonal retention and consistency of ridership
Location: work or play?
Day of the week: work or play?
Time of day
This turns into three main points for the marketing team at Cyclistic to focus on while designing their future marketing strategy to convert casual riders to members:
Seasonality
Use case
Usage time
Recommendations include:
Summer campaign that targets casual rider customers at their peak, offering a first-time member discount and/or showcasing the benefits of an annual membership with easy advertisement-friendly visuals, maybe even a summer membership
Create new member packages for entertainment— fun riders to have a referral program (you and a friend get x percent off if you sign up together) or partnership with entertainment venues/restaurants
Digital media/push notification campaign to alert casual users of the benefits of commuting regularly to work with a membership and its benefits